The Process
I initially wanted to use Java to create the project, since I though having experience creating a desktop applicaiton using Java would be a good preparation for the future. However, upon diving further into the nature of the project, I realized python would be the best application to use. Python already had pdf processing libraries that would allow me to extract pages easily. In addition, the files themselves were scanned into PDF documents, rather than being typed out and converted from word. This meant that I would have to use character recognition in order to parse the files. Thus, I felt that Python's use in image recognition and machine learning would be most useful.
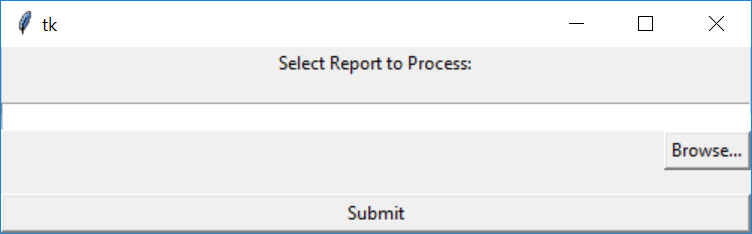
While Python was the best choice for the backend, unfortunately the GUI that python provides are not as user friendly as I would have hoped. I primarily used tkinter for my UI. While I found that this system had everything I needed, I felt that the User Interface that I created was not up to my standards. In the future, if I had more time to work on this project, I would have used a html browser to develop the front end and have the backend run off of python. However, the tkinter worked fine for a Minimum Viable Product for my desktop application with a project deadline of one month.
The desktop application's major bottleneck is the image recognition, which requires alot of proccessing power to read a 14 page document. I used the timing function within python to optimize the elapsed real time of the execution. However, I continuously found that the application would get caught in the image recongition phase, which will only improve as the hardware the program runs on will improve. However, I was able to optimize the application using regular expressions to parse the document, as well as using linear time operations. In addition, I wanted to create error handling in order to complete as much work as possible for the end user. I found that sometimes the OCR (optimal character recognition) algorithm sometimes had difficulty reading the text if the scan had noise. Thus, as a result, the system would crash when the document could not parse the individual's name. In order to solve this problem, I added filler text to the name of the file if the system could not recognize the name of the client, month, or client code. My hope would be that the user would quickly check the names of the files after the process was complete, and would change the file paths accordingly. The OCR fails only about 5% of the time, and there are multiple places that these data fields appear in the document which provide a second chance to be able to parse the document's critical information.
In order to visualize the scope of the project space, I included a diagram to show the flow of information within the system. This allows for a quick and easily visualization that also allowed me to plan the development of the code. In creating diagrams such as these, I was able to rationalize the structure of the code and plan for unforseen challenges.